인포메이트 7주차 공유(알고리즘)

인포메이트 7주차 공유(알고리즘) 모음입니다.
CSS 프로퍼티에 숨겨진 레이아웃 알고리즘 - 곽승주
Heap 메모리와 GC 알고리즘 - 윤해진
React reconciliation 알고리즘을 초간단하게 알아보자! - 김민재
재미와 이익을 위한 자바스크립트 전문화 - 김하나
CSS 프로퍼티에 숨겨진 레이아웃 알고리즘 - 곽승주
Intro
자주 사용했었던 CSS 코드가 예상치 못한 다른 결과를 낳은 적이 있었을 것입니다. 그 이유는 프로퍼티가 복잡한 시스템에서 작동하고, 프로퍼티의 작동 방식을 변경시키는 미묘한 컨텍스트가 있기 때문입니다. 이는 레이아웃 알고리즘과 연관되어 있습니다.
레이아웃 알고리즘
레이아웃 알고리즘이 뭘까요? 브라우저가 HTML을 렌더링할 때, 모든 요소는 기본 레이아웃 알고리즘을 사용하여 계산된 레이아웃을 갖습니다. 레이아웃 알고리즘에는 아래와 같은 것들이 포함됩니다.
- Flexbox
- Positioned
- Grid
- Table
- Flow
z-index를 예로 설명드리겠습니다. z-index는 보통 position과 함께 중첩 순서를 제어하는 데 사용되며, 겹쳐졌을 때 어느 요소가 위에 표시될지 결정하는 속성입니다. 이를 position없이 사용하면 당연히 제대로된 동작을 하지 않겠죠? 이는 레이아웃 알고리즘 중 Flow 레이아웃을 사용했기 때문입니다. Flow 레이아웃은 다른 레이아웃으로 특정짓지 않는 이상 default로 사용됩니다.
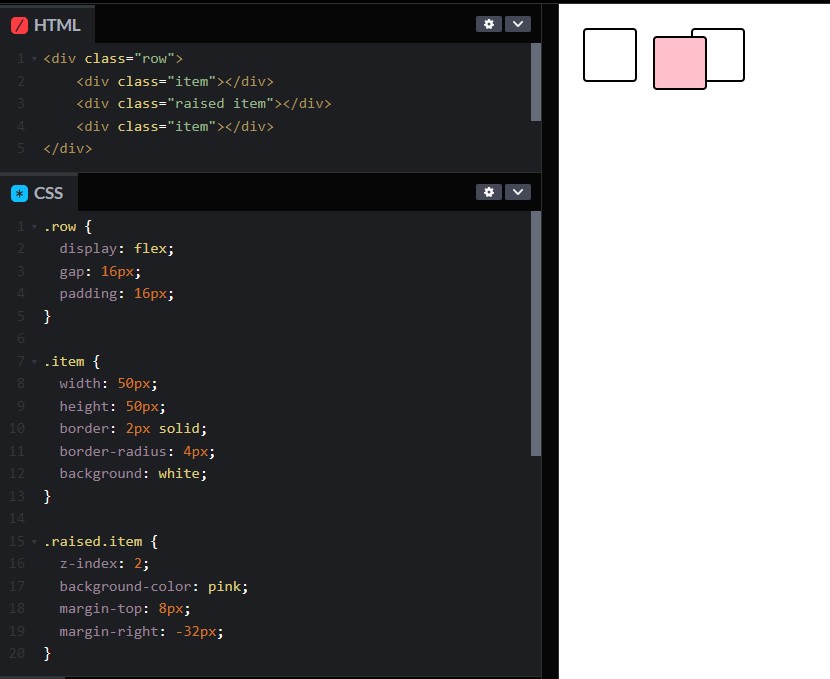
하지만, 위 예시를 보면 position을 사용하지 않고, flex를 사용하는 것으로도 z-index가 동작하는 것을 확인할 수 있습니다. 이것은 레이아웃 알고리즘 중 Flexbox 알고리즘이 z-index를 구현하기 때문입니다. 이처럼 각 레이아웃 알고리즘에 어떠한 프로퍼티를 구현할 수 있게 정의할 수 있고, 또한 일반적인 기본 동작을 재정의할 수도 있습니다. width로 그 예를 설명하겠습니다.
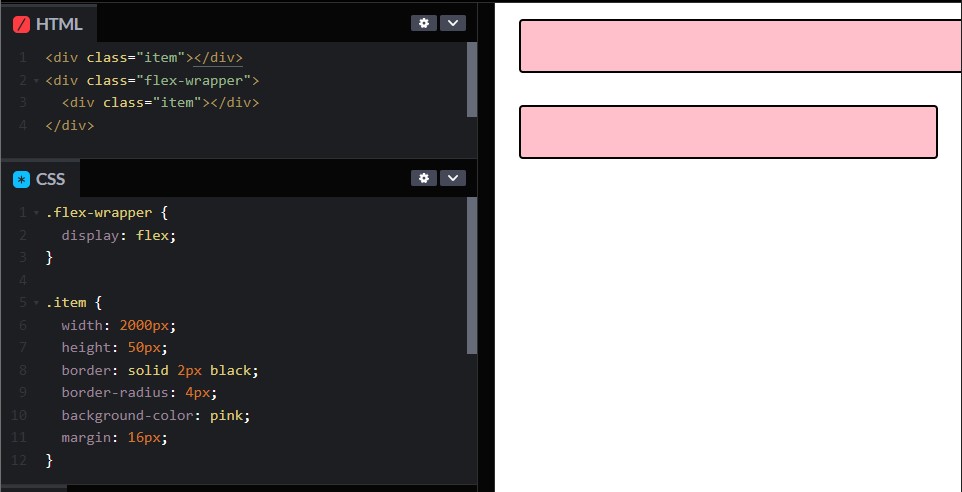
첫 div 태그는 Flow 레이아웃을 사용하여 렌더링되며, 실제로 2000px의 ��너비를 갖지만, 같은 속성을 갖는 flex-wrapper 내부의 div 태그는 Flexbox 레이아웃을 사용하고 있습니다. 이처럼 같은 속성을 가질지라도 레이아웃 알고리즘에 의해 다른 결과를 낳을 수 있게 됩니다.
충돌
만약 하나의 요소에 여러 레이아웃 알고리즘이 적용되면 어떻게 될까요?
<style>
.row {
display: flex;
}
.primary.item {
position: absolute;
}
</style>
<ul class="row">
<li class="item"></li>
<li class="primary item"></li>
<li class="item"></li>
</ul>
세 리스트 항목은 모두 Flex 컨테이너에 포함된 자식이므로, Flexbox 레이아웃에 따라 배치되어야 합니다. 그러나 두 번째 자식 요소는 position: absolute로 특정시켰기 때문에 Positioned 레이아웃 동작을 따릅니다.
이렇게 두 레이아웃이 충돌 시 요소는 제일 주된 레이아웃 모드를 사용하여 렌더링됩니다. 정확한 계층 구조는 모르지만, Positioned 레이아웃이 높은 우선순위를 갖는 경향이 있습니다. 따라서 두 번째 자식 요소는 Flexbox가 아닌 Positioned 레이아웃을 사용합니다.
일반적으로 의도적인 충돌을 발생시키는 경우가 대부분입니다. 그러나 요소가 예상대로 작동하지 않는 것을 확인한다면 사용 중인 레이아웃 알고리즘을 확인해볼 필요가 있습니다.
인라인 마법 공간(inline magic space)
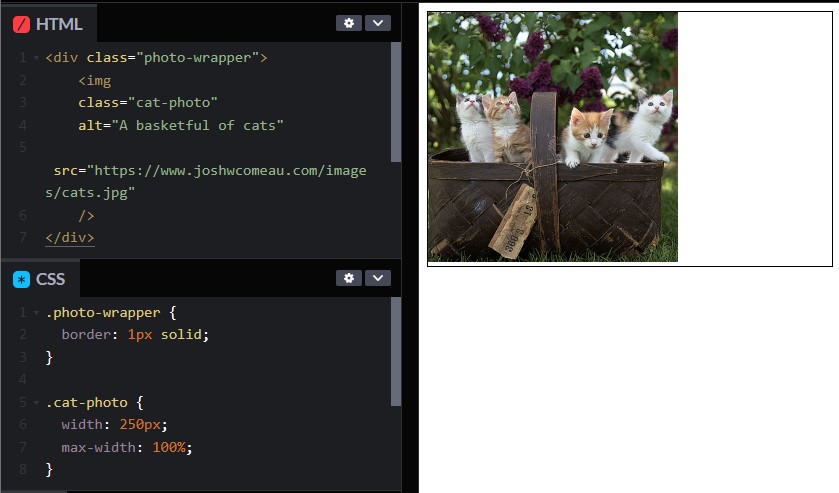
위 박스 안에 고양이 이미지가 있습니다. 단순 코드이며 padding이나 margin을 주지 않았는데 이미지 아래에 약간의 여백이 있는 것을 확인할 수 있습니다. 어떠한 레이아웃 알고리즘을 지정하지 않았기 때문에 Flow 레이아웃이라는 것을 유추할 수 있고, 그 Flow 레이아웃 때문에 아래 여백이 생긴다라고 생각할 수 있습니다. Flow 레이아웃은 인라인(inline) 또는 블록(block) 구조를 기반으로 합니다.
그리고 인라인 요소는 레이아웃의 일부가 아니라 단락 중간에 사용되는 경우가 많습니다. 그렇기 때문에 인라인 요소가 주변 텍스트의 가독성에 부정적인 영향을 주지 않도록 약간의 수직 공간(줄 간격)이 추가됩니다.
이러한 이유로 위 고양이 이미지 밑에 여백이 생긴 것도 이해가 될 것입니다. 이미지는 기본적으로 인라인 요소이기 때문입니다!
이를 해결하기 위한 가장 간단한 방법으로는 인라인 부분을 블록으로 처리하는 것입니다.
또한, 이 동작은 Flow 레이아웃에서만 해당하므로, 다른 레이아웃 알고리즘으로 전환해 문제를 해결할 수 있습니다 ex) display: flex;
마지막으로, line-height를 통해 추가 공간을 0으로 축소시켜 문제를 해결할 수도 있습니다.
결론
CSS는 많은 레이아웃 알고리즘이 있으며 모두 고유한 기법과 숨겨진 메커니즘이 있습니다. CSS 프로퍼티에만 집중한다면, 원하는 결과를 얻지 못했을 때 그 원인을 제대로 파악하지 못할 것입니다. 또한, 원하는 결과를 만들기 위해 부가적인 속성을 추가하는 방법으로 해결할 것입니다. 하지만, 레이아웃 알고리즘을 이해한다면, 적절한 레이아웃 알고리즘을 선택해 근본적인 문제를 해결할 수 있습니다.
참고자료
https://junghan92.medium.com/번역-레이아웃-알고리즘-이해하기-baed8b1eca5f
Heap 메모리와 GC 알고리즘 - 윤해진
들어가며)
Heap. 자료구조, 알고리즘 적으로는 꽤나 익숙하실 것입니다. 그러나 이번 주제로는 힙 메모리라는 영역과 그를 관리하는 가비지 컬릭터에 대해서 이야기해 보려 합니다.
Heap 메모리란
힙 메모리란 자바스크립트에서 참조 타입(객체 등) 데이터를 저장하기 위한, 메모리 할당을 하는 영역으로 js에서 동적으로 할당되는 데이터를 저장하는 공간입니다.
힙 메모리의 경우 변수가 생성되고 해제될 때까지 데이터를 유지하며, 할당 및 해제는 프로그램 실행 중 자동으로 이루어집니다. 힙은 스택과 달리 구조화되지 않은 자유 형식의 메모리 공간으로 필요에 따라 동적 확장 및 축소 가능합니다.
힙의 동적 메모리 할당
- 객체 및 함수
- 런타임에 크기를 알 수 있음
- 객체당 제한 없음
JS에서 힙 메모리의 중요성
js 엔진은 가비지 컬렉션을 통해 힙 메모리를 자동 관리합니다.
힙 메모리는 참조 타입 데이터(예: 객체, 함수)를 저장하는 데 사용되며, 프로그램의 동적 데이터가 저장되는 주요 공간입니다. 이 메모리 영역은 데이터가 필요한 동안 유지되며, 더 이상 필요하지 않을 때 자동으로 해제됩니다.
힙 메모리 관리의 효율성은 프로그램의 성능과 직결됩니다. 효율적인 메모리 관리는 메모리 누수를 방지하고, 애플리케이션의 반응성과 안정성을 유지하는 데 중요합니다. 메모리 누수는 미사용 메모리가 적절히 해제되지 않아 계속해서 메모리 사용량이 증가하는 현상을 말하며, 이는 결국 성능 저하나 애플리케이션의 실패를 초래할 수 있습니다.
GC: Garbage Collector
가비지 컬렉션은 메모리에서 더 이상 사용하지 않는 객체를 자동으로 검출하고 더 이상 쓰지 않는 버리는 값으로 판단하여 그 메모리 공간을 해제합니다.
이런 과정은 프로그램의 메모리 효율성을 보장하게 되며, 메모리 누수를 방지합니다.
그러면 어떻게 더 이상 사용하지 않는 메모리라고 판단하는 것일까요? 그리고 GC가 동작하는 동안 프로그램이 중단되는 시간을 줄일 수 있을까요? 이는 일부 알고리즘을 사용해 해결합니다.
-
Reference-counting garbage collection
이는 가리키는 참조가 없는 객체를 수집합니다.
객체가 생성될 때마다 해당 객체를 참조하는 변수, 속성, 또는 다른 객체들에 대한 참조 수가 증가하고, 참조가 해제될 때마다 감소합니다. 참조 수가 0이 되면, 즉 어떤 다른 객체나 변수도 해당 객체를 참조하고 있지 않을 때 해당 객체는 가비지로 간주되어 메모리에서 해제됩니다.
그러나 이 알고리즘의 경우 객체들 사이의 순환 참조가 발생하는 경우, 참조 수가 0이 되지 않는 경우가 있어 메모리 누수가 발생할 수 있습니다.
-
Mark-and-Sweep
'mark' 단계에서는 GC의 Root에서부터 모든 변수들을 스캔하며 각각 어떤 객체를 참조하고 있는지 찾아 마킹힙니다. 이는 참조되고 있는 객체와 참조되지 않은 객체들을 식별하는 과정입니다.
‘sweep’단계에서는 참조되지 않는 객체들을 Heap에서 제거합니다.
+Compact: 이는 알고리즘에 따라 추가될수도 있는 부분으로, Sweep 후, 분산된 객체들을 Heap의 시작 주소로 모아 메모리가 할당된 부분과 그렇지 않은 부분으로 나눕니다. (메모리 단편화 방지)
위 방법은 순환 참조로 인한 문제를 해결할 수 있으며, 지금의 js 엔진에서 많이 사용됩니다.
참고 글:
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management#garbage_collection
https://velog.io/@sejinkim/자바스크립트의-메모리-관리-설명
https://imasoftwareengineer.tistory.com/103
React reconciliation 알고리즘을 초간단하게 알아보자! - 김민재
React 18 부터 reconciliation 알고리즘이 바뀌었다는 사실 알고 계셨나요?
React reconciliation?
React Reconciliation은 React가 가상 DOM에 대한 변경 사항을 결정하고 해당 변경 사항을 실제 DOM에 적용하는 프로세스에요! ui가 기본 데이터와 동기화된 상태를 유지하여 불필요한 업데이트를 최소화하고 필요한 구성 요소만 렌더링하도록 보장하죠.
예전 버전의 React에서는 "diffing" 또는 "tree diffing"이라고도 알려 알고리즘을 사용했답니다! 이전 및 현재 가상 DOM 트리를 비교하여 차이점을 식별하고 그에 따라 영향을 받는 구성 요소를 업데이트하는 방식이었죠. 하지만 이 접근 방식에는 특히 크고 복잡한 구성 요소 계층을 처리할 때 제한이 있었어요..
React 18에서는?
React 18에서는 더 향상된 reconciliation 알고리즘을 사용해요! 들어보셨나요? ‘Concurrent mode!’
Concurrent mode를 사용하면 React가 메인 스레드를 차단하지 않고 동시에 여러 작업을 수행할 수 있으므로 응답성이 향상되고 사용자 경험이 더 원활해진답니다.
"Concurrent React"로 알려진 React 18의 새로운 조정 알고리즘은 조정 작업을 "fiber"라고 하는 더 작은 단위로 나누고 중요도에 따라 우선순위를 지정해요. 이 접근 방식을 통해 React는 조정 프로세스를 효율적으로 중단하고 재개하죠. 다르게 이야기하자면 사용자 상호 작용 및 기타 우선 순위가 높은 작업의 우선 순위를 지정할 수 있어요!
React reconciliation 주요 개념 정리
Fiber Reconciliation
- React 18의 reconciliation 프로세스는 fiber 수준에서 작동한다고 했었죠? fiber는 쉽게 이야기 하자면 구성 요소와 해당 작업을 나타내요. 조정 작업을 더 작은 fiber로 분할함으로써 React는 이를 보다 효율적으로 관리하고 우선순위를 지정할 수 있게 되는거에요.
Render Phase and Commit Phase
- reconciliation 프로세스는 rendering, commit 단계라는 두 가지 주요 단계로 나눌 수 있어요. rendering 단계에서 React는 구성 요소 트리를 탐색하여 Fiber를 생성하거나 업데이트하죠. 렌더링해야 하는 구성 요소를 결정하고 빨리 해결되어야 하는 업데이트를 먼저 우선 순위 목록으로 올려요.
- commit 단계는 React는 변경 사항을 실제 DOM에 적용하는 단계에요. 이 때도 마찬가지로 여러 우선 순위 레벨로 나누어져 React가 성능 저하 없이 중요한 업데이트의 우선 순위를 지정하고 ui에 응답할 수 있도록 하지요. 간단하게 react v18의 reconciliation 알고리즘을 알아봤어요! 정말 간단하게 이야기 했기때문에 reconciliation 을 더자세히 알고 싶다면 아래 글을 완독해보는것도 좋아요~!
react의 Lane model과 concurrent render 자세히 알아보기
https://goidle.github.io/react/in-depth-react18-intro/
https://goidle.github.io/react/in-depth-react18-lane/
https://goidle.github.io/react/in-depth-react18-transition_1/
https://goidle.github.io/react/in-depth-react18-transition_2 copy/
https://goidle.github.io/react/in-depth-react18-concurrent_render/
재미와 이익을 위한 자바스크립트 전문화? - 김하나
https://velog.io/@surim014/optimizing-javascript-for-fun-and-for-profit#9-전문화specialization-사용하기
이 글은 JavaScript 최적화 방법에 대한 내용을 소개합니다.
이중에서 9번 챕터인 전문화(specialization) 에 관련해 흥미롭게 느낀 부분을 중심으로 설명하겠습니다. 이외의 내용이 궁금하신 분들은 위 글의 나머지 챕터들을 읽어보시기 바랍니다.
전문화
전문화는 특정 사용 사례의 제약 조건을 로직에 맞추는 것입니다.
일반적으로 한 조건이 다른 조건보다 더 자주 발생한다고 판단될 때, 이를 파악하고 해당 조건에 맞게 코드를 작성할 수 있습니다.
예를 들어, 어떤 제품 목록에 태그를 추가해야 하는 상황에서, 태그가 대부분 비어있다는 것을 알게 되었다고 가정해보겠습니다.
따라서 이 상황에 맞추어 전문화를 적용하고 이에 대해 설명하겠습니다.
다음과 같이 예시 물품과 태그를 정의합니다.
const descriptions = ['apples', 'oranges', 'bananas', 'seven']
const someTags = {
apples: '::promotion::',
}
const noTags = {}
그런 다음, 전문화를 적용하지 않은 문자열 변환 함수를 살펴보겠습니다.
// 해당되는 경우 태그와 함께 제품을 문자열로 전환합니다.
function productsToString(description, tags) {
let result = ''
description.forEach(product => {
result += product
if (tags[product]) result += tags[product]
result += ', '
})
return result
}
이와 다르게 빈태그를 먼저 걸러주는 전문화가 적용된 동일한 기능 함수를 만들어줍니다.
function productsToStringSpecialized(description, tags) {
// 우리는 `tags`가 비어 있을 가능성이 있다는 것을 알고 있으므로 미리 한 번 확인한 다음 내부 루프에서 `if` 검사를 제거할 수 있습니다.
if (isEmpty(tags)) {
let result = ''
description.forEach(product => {
result += product + ', '
})
return result
} else {
// 문자열 전환 로직은 동일
}
}
function isEmpty(o) { for (let _ in o) { return false } return true }
이 두개의 함수를 가지고 실제 비교했을 때의 수치 비교는 다음과 같이 나타납니다.
- non speciailized : 85.71 %
- specialized : 100 %
위와 같은 상황에서는 다음과 같은 알고리즘 적용을 통해 성능이 더 높아질 수는 있지만, 조건이 달라진다면 다르게 판단해야 할 필요가 있을것입니다.
(코드에서의 분기 측변에서도 제거하는게 더 효율적이다 라는 이면이 있기에.. 대표 예시)
reference : https://velog.io/@surim014/optimizing-javascript-for-fun-and-for-profit#9-전문화specialization-사용하기
https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array